處理網頁伺服器的阻擋:
網頁伺服器有時會根據請求的來源來決定是否允許訪問。如果伺服器發現我們是使用程式(如 Python 爬蟲)來訪問,可能會拒絕請求。為了避免這種情況,我們可以讓爬蟲偽裝成瀏覽器來繞過這些檢查。
技巧:使用 User-Agent 偽裝成瀏覽器。
解析動態加載的內容:
有些網頁的內容是透過 JavaScript 動態加載的,這樣的網頁用普通的爬蟲技術是無法直接取得內容的。
技巧:使用 Selenium 模組來模擬瀏覽器操作。
儲存下載的網頁:
有時候我們需要將爬取的網頁數據儲存到檔案中,方便後續分析或記錄。
技巧:使用 with open 將網頁內容寫入自己的電腦。
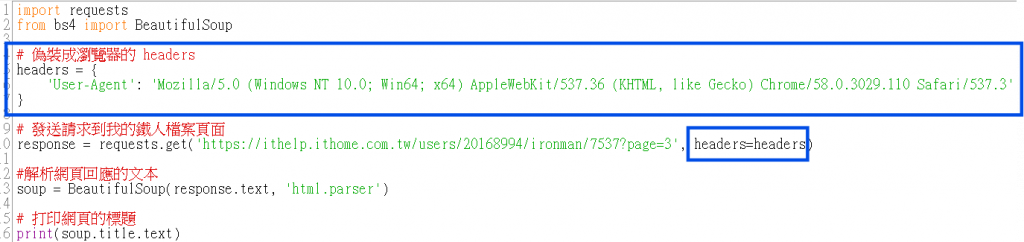
要找適合的 User-Agent,可以參考瀏覽器本身的請求標頭或使用線上資源來模仿真實的瀏覽器。例如 https://www.whatismybrowser.com/ 有提供各種瀏覽器的 User-Agent。這裡就不多做贅述>"<

403 Forbidden 錯誤。

403 Forbidden 代表服務器已經理解請求,但是拒絕執行它。
pip install selenium 即可。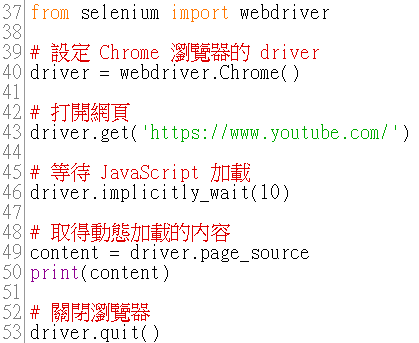
driver = webdriver.Chrome():
使用 Selenium 建立一個 Chrome 瀏覽器的 driver。Selenium 支援多個瀏覽器(如 Firefox、Safari、Edge),但這裡我們選擇使用 Chrome 瀏覽器。
driver.get('https://www.youtube.com/'):
讓瀏覽器開啟 https://www.youtube.com/ 網站,並呈現網站內容,和在手動操作時輸入網址後按下 Enter 一樣。
driver.implicitly_wait(10):
設定一個隱式等待(Implicit Wait)的時間。這裡的 10 表示瀏覽器會等最多 10 秒,讓所有元素、內容、JavaScript 代碼都能完成加載。特別是 YouTube 這種大型網站, JavaScript 加載需要一些時間。
隱式等待:讓程式在等待過程中不會立即拋出錯誤,而是會嘗試在 10 秒內重複檢查頁面是否已完全加載。與顯式等待不同,隱式等待可以等待網頁內的所有元素加載完成。
content = driver.page_source:
從瀏覽器中取得網頁的完整 HTML 原始碼,包括動態加載的部分,並且在下一行打印出來。這是 Selenium 厲害的地方,它可以抓取使用 JavaScript 動態生成的內容,這在單純的 HTTP 請求中是無法做到的。
driver.quit():
關閉瀏覽器並結束 WebDriver 的會話。這是非常重要的一步,因為如果不關閉瀏覽器,程式可能會繼續佔用資源,導致電腦變慢。

with open('downloaded_page.html', 'w', encoding='utf-8') as f:
使用 Python 的內建函數 open() 來打開一個名為 downloaded_page.html 的檔案。 'w' 代表開啟這個檔案以寫入模式,如果檔案不存在則會自動創建。encoding='utf-8' 指定了 UTF-8 編碼,這是為了正確處理網頁中的字元,特別是非英文的字元(如中文)。
f.write(response.text):
將伺服器回應中的 HTML 內容(即 response.text)寫入剛剛打開的 downloaded_page.html 檔案中,這樣網頁內容就會被儲存在自己的電腦裡。
檢查狀態碼:
可以檢查網頁請求是否成功,狀態碼為 200 代表成功,其他狀態碼表示失敗或頁面不存在。
確認狀態碼為200後,可以到執行Python腳本的目錄中,找到downloaded_page.html 檔案,點擊後會直接打開我們下載的網頁。
今天學習了如何使用 User-Agent 偽裝成瀏覽器、使用 Selenium 模組來模擬瀏覽器操作,和使用 with open 將網頁內容寫入自己的電腦。透過學習爬蟲,我了解了網頁的結構,知道如何使用 Python 來與網頁互動。在這過程中我遇到不少挑戰,比如有些網站的結構會不斷改變等,導致我原本的程式碼無法正常運行 Q_Q
也讓我意識到,學習爬蟲不僅僅是寫出一段程式碼,更是要學會如何快速適應變化和解決問題。此外,有時候還需要處理網站的防爬蟲機制,不能隨意的存取網頁,這讓我更明白網頁的使用守則有多麼重要><

